redis-基础">Redis 基础
redis">什么是 Redis?
Redis (REmote DIctionary Server)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
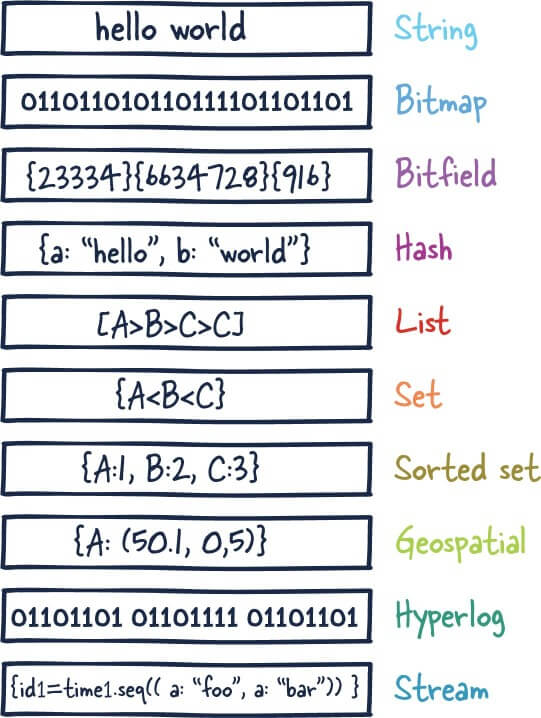
Redis 数据类型概览
Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
个人学习的话,你可以自己本机安装 Redis 或者通过 Redis 官网提供的在线 Redis 环境(少部分命令无法使用)来实际体验 Redis。
redis" height="451" src="https://img-blog.csdnimg.cn/img_convert/ae04c6379ff9d04297bbc84c70d7031f.png" width="800" />
try-redis
全世界有非常多的网站使用到了 Redis ,techstacks.io 专门维护了一个使用 Redis 的热门站点列表 ,感兴趣的话可以看看。
redis-为什么这么快">Redis 为什么这么快?
Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
- Redis 基于内存,内存的访问速度比磁盘快很多;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
- Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
- Redis 通信协议实现简单且解析高效。
下面这张图片总结的挺不错的,分享一下,出自 Why is Redis so fast? 。
 why-redis-so-fast
why-redis-so-fast
那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高且 Redis 提供的数据持久化仍然有数据丢失的风险。
redis-和-memcached-的区别和共同点">说一下 Redis 和 Memcached 的区别和共同点
共同点:
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
redis">为什么要用 Redis?
1、访问速度更快
- 都是基于内存的数据库,一般都用来当做缓存使用。
- 都有过期策略。
- 两者的性能都非常高。
-
区别:
- 数据类型:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
- 数据持久化:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制而 Memcached 没有。
- 集群模式支持:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 自 3.0 版本起是原生支持集群模式的。
- 线程模型:Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 针对网络数据的读写引入了多线程)
- 特性支持:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
- 过期数据删除:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
2、高并发
一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
3、功能全面
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
redis-module-有什么用">什么是 Redis Module?有什么用?
Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特殊的需求。这些 Module 以动态链接库(so 文件)的形式被加载到 Redis 中,这是一种非常灵活的动态扩展功能的实现方式,值得借鉴学习!
我们每个人都可以基于 Redis 去定制化开发自己的 Module,比如实现搜索引擎功能、自定义分布式锁和分布式限流。
redis-应用">Redis 应用
redis-除了做缓存-还能做什么">Redis 除了做缓存,还能做什么?
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:分布式锁详解 。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
下面是Stream 用作消息队列时常用的命令:
XADD:向流中添加新的消息。XREAD:从流中读取消息。XREADGROUP:从消费组中读取消息。XRANGE:根据消息 ID 范围读取流中的消息。XREVRANGE:与XRANGE类似,但以相反顺序返回结果。XDEL:从流中删除消息。XTRIM:修剪流的长度,可以指定修建策略(MAXLEN/MINID)。XLEN:获取流的长度。XGROUP CREATE:创建消费者组。XGROUP DESTROY: 删除消费者组XGROUP DELCONSUMER:从消费者组中删除一个消费者。XGROUP SETID:为消费者组设置新的最后递送消息 IDXACK:确认消费组中的消息已被处理。XPENDING:查询消费组中挂起(未确认)的消息。XCLAIM:将挂起的消息从一个消费者转移到另一个消费者。XINFO:获取流(XINFO STREAM)、消费组(XINFO GROUPS)或消费者(XINFO CONSUMERS)的详细信息。
Stream 使用起来相对要麻烦一些,这里就不演示了。
总的来说,Stream 已经可以满足一个消息队列的基本要求了。不过,Stream 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
redis-可以做搜索引擎么">Redis 可以做搜索引擎么?
Redis 是可以实现全文搜索引擎功能的,需要借助 RediSearch ,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
- 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
- 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。






